
Ruby est aussi très à l’aise en mode 'script'. Il peut remplacer `sed`, `grep`, `awk`, ...
L’option -e permet de spécifier le script directement en argument.
Un des points communs aux différents utilitaires est le traitement ligne par ligne. Bien qu’il soit possible de faire une boucle dans le code, il sera souvent plus pratique d’utiliser l’option -n ou -p qui activera le traitement ligne par ligne.
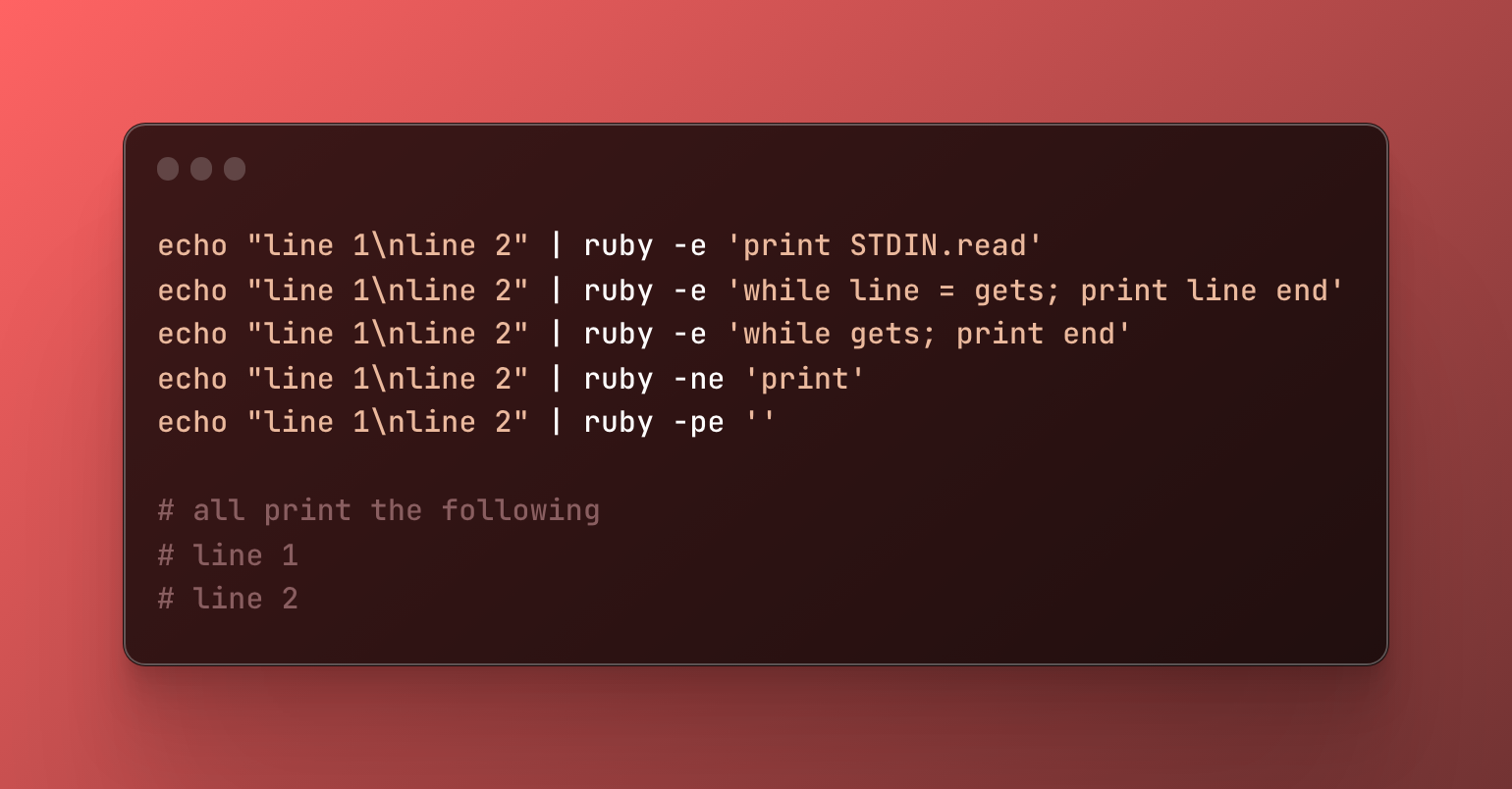
La documentation est d’ailleurs très explicite sur ces 2 options !
-n assume 'while gets(); ... end' loop around your script
-p assume loop like -n but print line also like sed
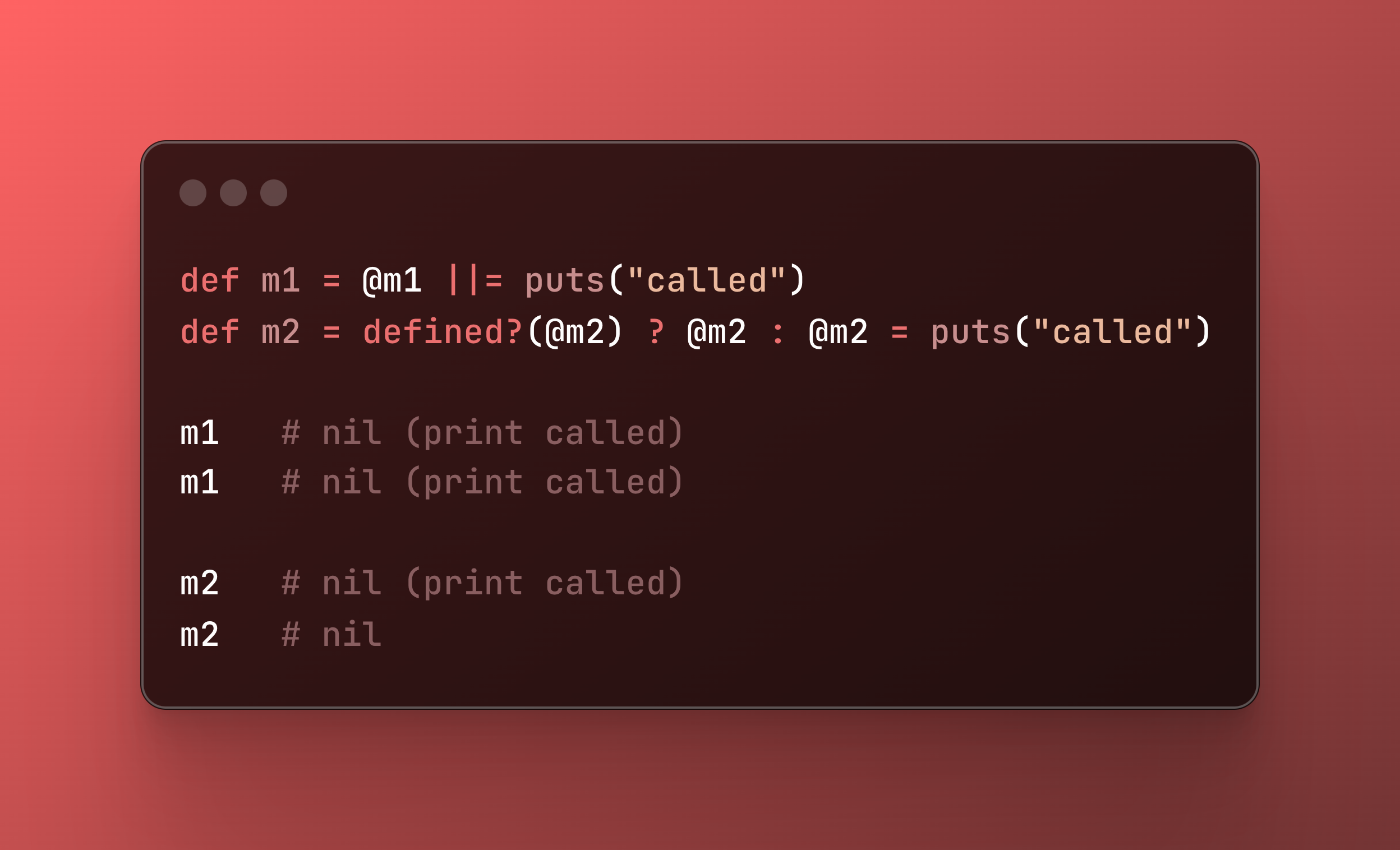
Le traitement ligne par ligne repose sur 2 variables globales spéciales et le comportement par défaut de print :
$/est le séparateur utilisé pour identifier une ‘ligne’, par défaut vaut\n.$_contient la dernière ‘ligne’ lue avecgets. ⚠️ Le séparateur est inclut dans$_.printsans argument affiche le contenu de la variable$_.
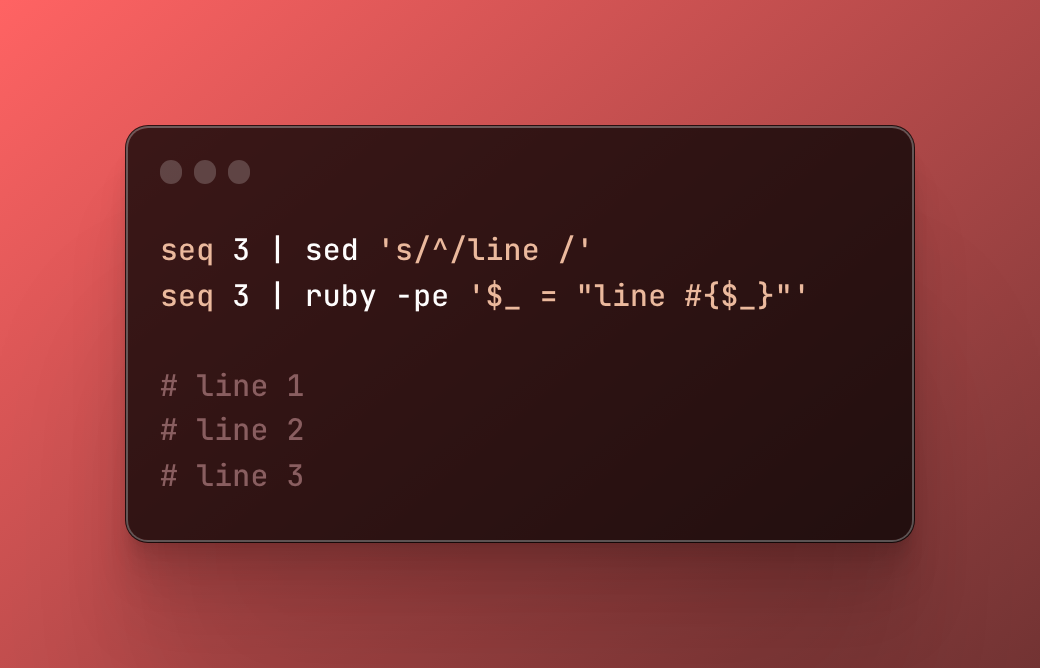
Ex 1 : Besoin d’ajouter un préfixe à chaque ligne ?
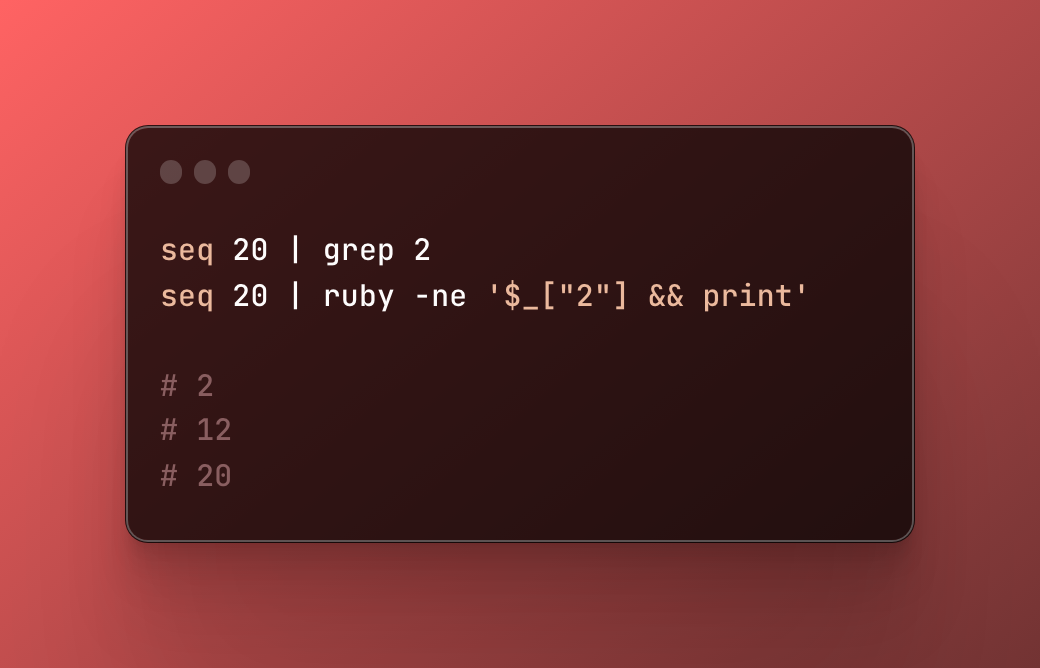
Ex 2 : Besoin de filtrer les lignes contenant un 2 ? (En utilisant slice !)
Ex 3 : Besoin de faire un total ? (comme awk Ruby a les blocs BEGIN et END !)

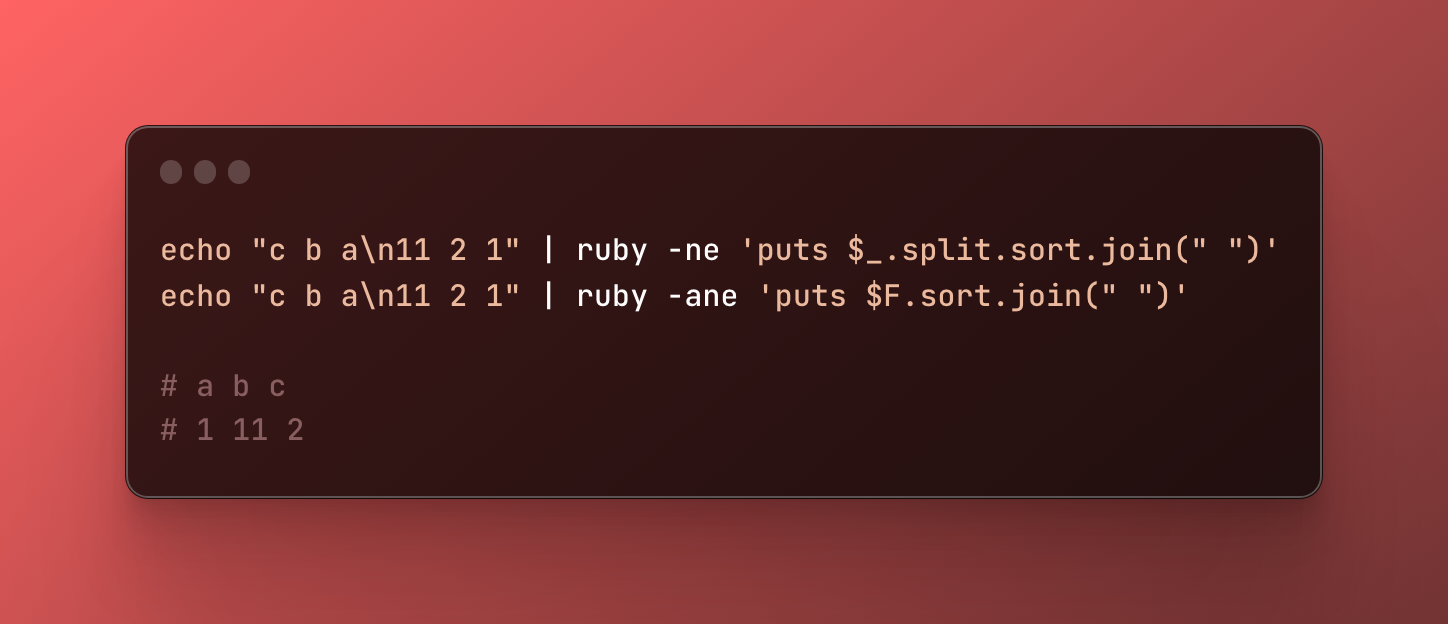
Un dernier exemple où Ruby sera plus appréciable. Trier les mots de chaque ligne dans l’ordre alphabétique. On pourra même utiliser l’option -a (autosplit) pour récupérer chaque colonne dans une autre variable global spécial $F agissant ainsi encore plus comme awk !
Les liens vers la documentation Ruby des arguments de ligne de commande, du man et de BEGIN / END (il y a d’ailleurs une erreur dans leur exemple, le voyez-vous ?).
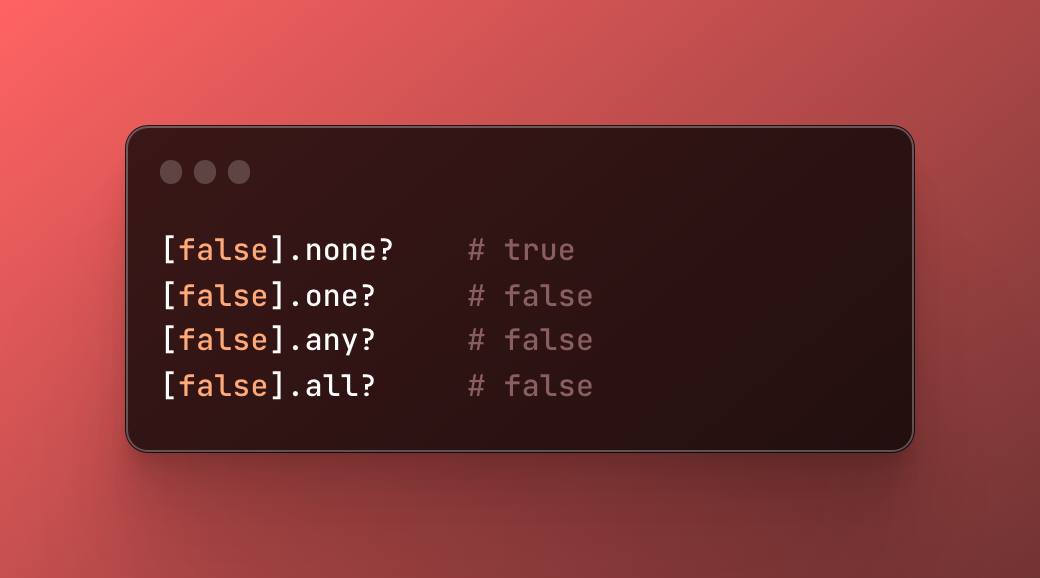
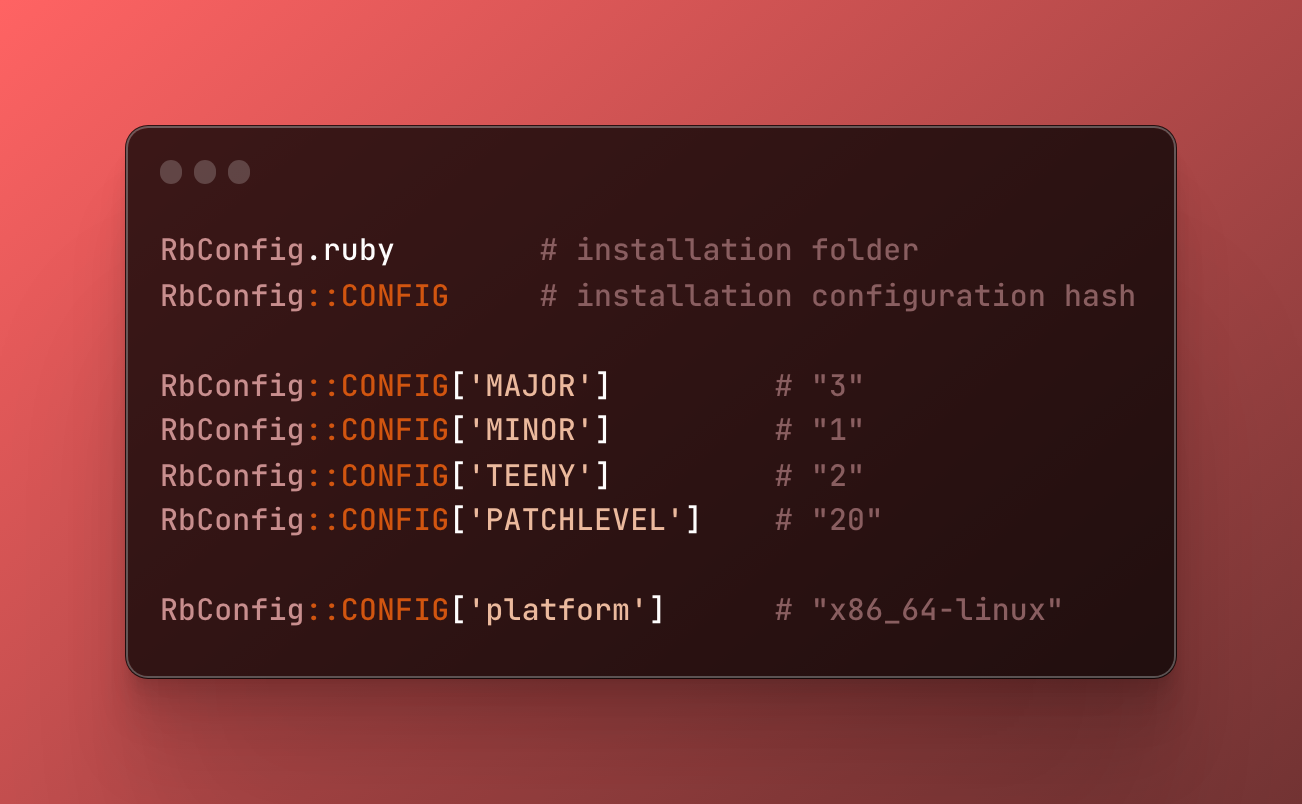
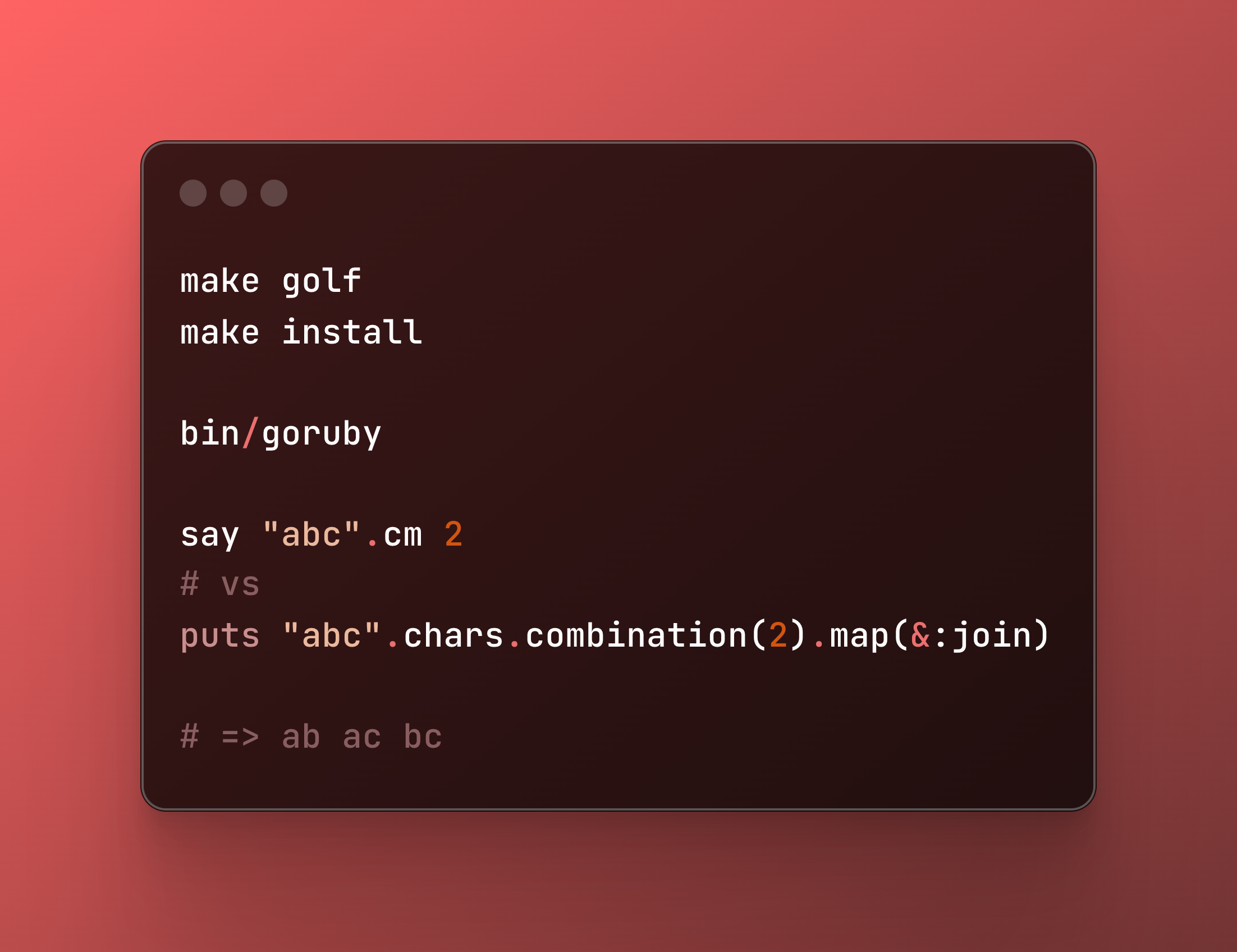
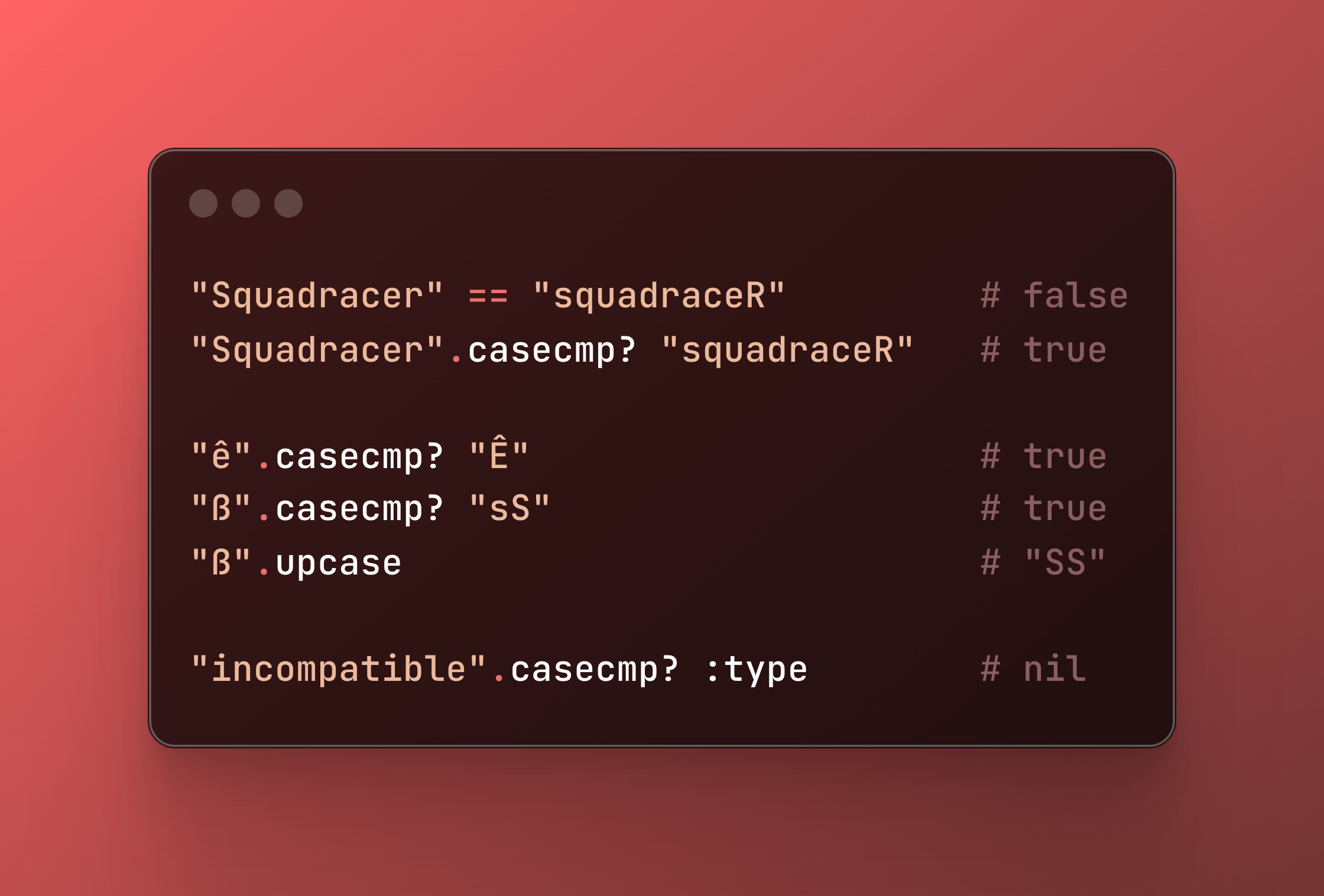
{kind=link}